

https://school.programmers.co.kr/learn/courses/30/lessons/42890
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
🎁 문제
프렌즈대학교 컴퓨터공학과 조교인 제이지는 네오 학과장님의 지시로, 학생들의 인적사항을 정리하는 업무를 담당하게 되었다.
그의 학부 시절 프로그래밍 경험을 되살려, 모든 인적사항을 데이터베이스에 넣기로 하였고, 이를 위해 정리를 하던 중에 후보키(Candidate Key)에 대한 고민이 필요하게 되었다.
후보키에 대한 내용이 잘 기억나지 않던 제이지는, 정확한 내용을 파악하기 위해 데이터베이스 관련 서적을 확인하여 아래와 같은 내용을 확인하였다.
- 관계 데이터베이스에서 릴레이션(Relation)의 튜플(Tuple)을 유일하게 식별할 수 있는 속성(Attribute) 또는 속성의 집합 중, 다음 두 성질을 만족하는 것을 후보 키(Candidate Key)라고 한다.
- 유일성(uniqueness) : 릴레이션에 있는 모든 튜플에 대해 유일하게 식별되어야 한다.
- 최소성(minimality) : 유일성을 가진 키를 구성하는 속성(Attribute) 중 하나라도 제외하는 경우 유일성이 깨지는 것을 의미한다. 즉, 릴레이션의 모든 튜플을 유일하게 식별하는 데 꼭 필요한 속성들로만 구성되어야 한다.
제이지를 위해, 아래와 같은 학생들의 인적사항이 주어졌을 때, 후보 키의 최대 개수를 구하라.

위의 예를 설명하면, 학생의 인적사항 릴레이션에서 모든 학생은 각자 유일한 "학번"을 가지고 있다. 따라서 "학번"은 릴레이션의 후보 키가 될 수 있다.
그다음 "이름"에 대해서는 같은 이름("apeach")을 사용하는 학생이 있기 때문에, "이름"은 후보 키가 될 수 없다. 그러나, 만약 ["이름", "전공"]을 함께 사용한다면 릴레이션의 모든 튜플을 유일하게 식별 가능하므로 후보 키가 될 수 있게 된다.
물론 ["이름", "전공", "학년"]을 함께 사용해도 릴레이션의 모든 튜플을 유일하게 식별할 수 있지만, 최소성을 만족하지 못하기 때문에 후보 키가 될 수 없다.
따라서, 위의 학생 인적사항의 후보키는 "학번", ["이름", "전공"] 두 개가 된다.
릴레이션을 나타내는 문자열 배열 relation이 매개변수로 주어질 때, 이 릴레이션에서 후보 키의 개수를 return 하도록 solution 함수를 완성하라.
제한사항
- relation은 2차원 문자열 배열이다.
- relation의 컬럼(column)의 길이는 1 이상 8 이하이며, 각각의 컬럼은 릴레이션의 속성을 나타낸다.
- relation의 로우(row)의 길이는 1 이상 20 이하이며, 각각의 로우는 릴레이션의 튜플을 나타낸다.
- relation의 모든 문자열의 길이는 1 이상 8 이하이며, 알파벳 소문자와 숫자로만 이루어져 있다.
- relation의 모든 튜플은 유일하게 식별 가능하다.(즉, 중복되는 튜플은 없다.)
입출력 예
relation / result
| [["100","ryan","music","2"],["200","apeach","math","2"], ["300","tube","computer","3"],["400","con","computer","4"], ["500","muzi","music","3"],["600","apeach","music","2"]] |
2 |
📢 풀이
2019년 카카오의 기출문제로 따로 알고리즘을 적용하는 문제는 아니다. 즉, 단순 구현 문제라고 볼 수 있다.
해당 문제는 데이터베이스의 후보키에 관련한 문제로 우선 후보키에 대해서 정확하게 알아야 한다.
후보키란? 유일성과 최소성을 동시에 만족하는 것이다.
위의 예제를 살펴보면 첫번째열의 100,200,300,400,500,600에 중복된 값이 없기 때문에 유일성을 만족한다. 그리고 하나의 열이므로 최소성도 자동으로 만족하게 되는 것이다.
최소성이라는 개념에 대해서 와닿지 않을 수 있다. 쉽게 예제로 풀어보겠다.
예를 들어 첫번째 열과 두번째 열을 합쳐보자 (100, ryan), (200, apeach) ... (600, apeach) 즉, 이것도 유일성을 만족한다. 그러나 이미 첫번째 열은 후보키이므로 이는 최소성을 만족하지 못한다.
만약 그러면 두번째열과 세번째열을 합친다면 (ryan, music), (apeach, math), ... (apeach, music) 이된다. 중복되는 값이 없으므로 유일성을 만족한다. 두번째열과 세번째열을 따로 생각해보면 이는 후보키가 될 수 있는가? 중복된 값(apeach, music)이 있기 때문에 후보키가 될 수 없다. 그러므로 이는 최소성을 만족하는 것이다.
후보키의 개념을 적립했고 그럼 이 문제는 어떻게 접근해야 할까?
우선 필자는 조합을 선택했다. C++의 next_permutation 알고리즘을 활용하여 모든 조합을 계산했다.
첫번째 열을 0 마지막 열을 3으로 위의 예제에 적용해보면 다음과 같은 조합이 나올 수 있다.
=> 0, 1, 2, 3, 01, 02, 03, 12, 13, 23, 012, 013, 023, 123, 01234
해당 열에 대해서 가장 먼저 유일성을 체크하고자 한다. 가장 쉬운 방법은 열들을 string으로 겹쳐서 중복체크를 해주면 된다. 예를 들어 5번째인 01의 경우에는 0번째 열과 1번째 열을 참고한다는 뜻으로 (100, ryan), (200, apeach) ... (600, apeach) 값들이 존재한다. 이를 문자열로 만들면 "100ryan", "200apeach", ... , "600apeach" 가된다. 이를 set에 넣어보면 중복된 값이 없으므로 사이즈가 6이 나올 것이다. set의 사이즈와 vector가 가지고있는 열의 사이즈가 같기 때문에 이는 유일성을 만족하게 된다. (set은 중복처리를 막기 때문에 중복이 발생할 경우 사이즈는 반드시 6보다 작습니다)
그럼 이제 유일성 체크는 완료했고 최소성은 어떻게 확인할 수 있을까? 만약 유일성을 만족하는 것들이 다음과 같다고 가정해보자
=> 0, 01, 02, 03
위의 숫자들이 모두 문자열로 되어있다면 01, 02, 03에 0이라는 부분 문자열이 속한다는 것을 알 수 있다. 그러므로 이들은 최소성을 만족하지 못한다. 즉, 위의 4가지 중에서는 0만 후보키가 될 수 있는 것이다.
이는 find algorithm을 쓰면 쉽게 구현할 수 있다.
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
int solution(vector<vector<string>> relation) {
int answer = 0;
vector<string> unique_index;
int tuple_size = relation[0].size();
//unique
for (int i = 1; i <= tuple_size; i++) {
vector<int> t(tuple_size - i);
for (int j = 0; j < i; j++) t.push_back(1);
do {
vector<int> index;
vector<string> cols(relation.size(), "");
for (int i = 0; i < t.size(); i++)
if (t[i] == 1) index.push_back(i);
for (int i = 0; i < index.size(); i++)
for (int j = 0; j < relation.size(); j++)
cols[j] += relation[j][index[i]];
set<string> s(cols.begin(), cols.end());
if (s.size() == cols.size()) {
string t;
for (int i = 0; i < index.size(); i++)
t.push_back(index[i] + '0');
unique_index.push_back(t);
}
} while (next_permutation(t.begin(), t.end()));
}
//min
set<int> dup_index;
for (int i = 0; i < unique_index.size(); i++) {
int ans_size = unique_index[i].size();
for (int j = i + 1; j < unique_index.size(); j++) {
int cnt = 0;
for (int k = 0; k < ans_size; k++) {
if (find(unique_index[j].begin(), unique_index[j].end(), unique_index[i][k]) != unique_index[j].end()) cnt++;
}
if (cnt == ans_size) {
dup_index.insert(j);
}
}
}
return unique_index.size() -dup_index.size();
}
결과는 ....

📢 결론
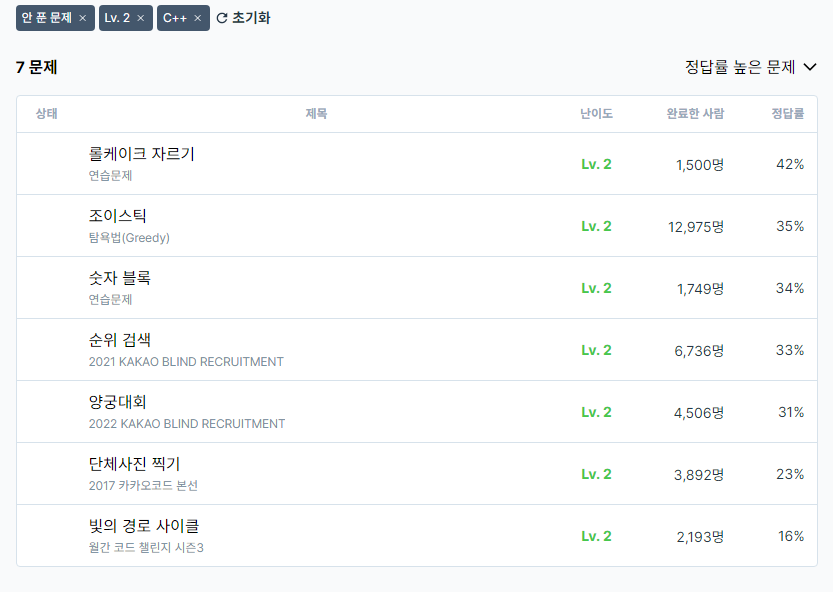
Lv. 1은 모두 다풀었고 이제 Lv. 2도 7문제만 남았다. 정답률이 높은 순으로 풀다보니 이제 정말 어려운 문제들만 남은 것 같다 ㅠㅠ..
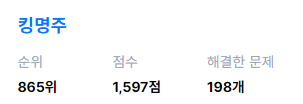
그래도 1000등 안에 들어가서 기분은 좋다 ^ 3^
'코테준비' 카테고리의 다른 글
| [PROGRAMMERS] Level 3 불량 사용자(카카오 기출, C++) (0) | 2022.12.29 |
|---|---|
| [PROGRAMMERS] Level 3 단속카메라(구현, C++) (0) | 2022.12.28 |
| [PROGRAMMERS] Level 2 큰 수 만들기 (스택, C++) (0) | 2022.12.15 |
| [PROGRAMMERS] Level 2 두개 이하로 다른 비트 (이진탐색, JAVA) (0) | 2022.12.13 |
| [PROGRAMMERS] Level 2 디펜스 게임 (이진탐색, C++) (0) | 2022.12.11 |