
코딩테스트에서 주로 자료구조를 묻는 문제들이 많이 나온다. 이 때, 왜 해당 알고리즘을 사용했는지, 어떤 상황에서 쓰이는지 정도는 숙지하고 있어야 한다.
👉 예상질문
Data Structure
1. 배열과 Linked List의 차이는 무엇인가요?
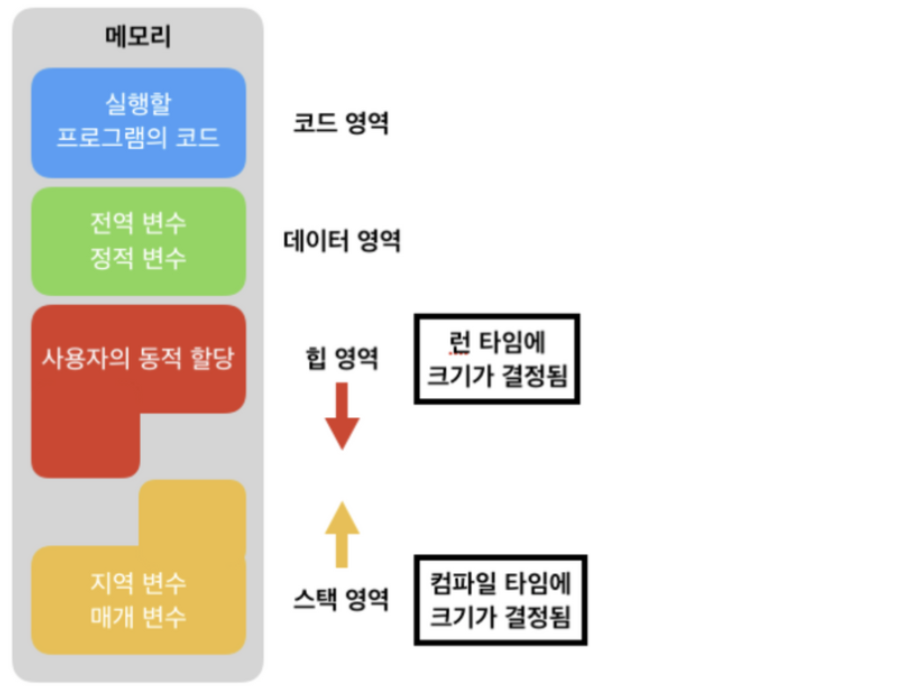
배열은 메모리상에 순서대로 데이터를 저장하고 링크드 리스트는 다음 데이터의 위치에 대한 포인터를 가지고 있는 구조입니다. 배열은 데이터를 인덱스로 조회할 수 있기 때문에 빠르게 탐색을 수행할 수 있고 링크드 리스트는 중간에 데이터를 삽입하거나 삭제하는 것이 용이하다는 장점이 있습니다. 또한 배열은 Stack 영역에 메모리가 할당이되고 링크드 리스트는 Heap 영역에 할당이 됩니다.
<참고>
배열 조회: O(1)
링크드 리스트 조회: O(N) /데이터 추가 삭제는 O(1)로 가능
출처: https://velog.io/@tonic523/%ED%9E%99-%EC%98%81%EC%97%AD-vs-%EC%8A%A4%ED%83%9D-%EC%98%81%EC%97%AD
2. List와 Set의 차이는 무엇인가요?
List는 중복된 데이터를 저장하고 들어온 순서를 유지하는 선형 자료구조이고 Set은 중복되지 않은 데이터를 저장하며들어온 순서를 유지하지 않는 선형 자료구조입니다. (TreeSet과 같이 순서를 유지하는 Set도 존재)
<참고>
3. Hash Function과 Hash Table에 대해서 설명해주세요.
해시 테이블은 키에 결과 값을 저장하는 자료구조입니다. 키와 값은 1대1로 매핑되어 있으며 키를 이용하여 값을 도출할 수 있습니다.
해시 함수는 키를 해시 값으로 변경해주는 역할을 수행합니다. 해시 함수의 대표적인 예로는 key를 테이블 크기로 나누어 나온 나머지를 인덱스로 사용하는 Division Method, Key의 문자열을 ASCII 코드로 바꾸고 그 값을 합해 테이블 내의 주소로 사용하는 Digit Folding 방식 등이 있습니다. 또한, 서로 다른 키가 같은 해시가 되는 경우를 해시 충돌이라고 하는데, 해시 충돌을 일으키는 확률을 최대한 줄이는 함수를 만드는 것이 중요합니다.
해시테이블의 저장/삭제/조회 평균 시간복잡도는 O(1)
4. Hash Collision에 대해서 설명해주세요.
해시 함수를 통해 index값을 구했을 때 중복이 생기는 경우는 해쉬 충돌이라고 합니다. 충돌 해결법으로는 분리 연결법, 개방 주소법이 있습니다.
분리 연결법(separate Chaining)은 버킷에 대해 연결 리스트, 트리 등의 자료구조를 활용해서 다음 데이터의 주소를 저장하는 것입니다.
개방 주소법(Open Addressing)은 chaining과는 다르게 연산을 통해 비어있는 해시 테이블의 공간을 활용하는 방법입니다.
대표적인 예로는 Linear Probing, Quadratic Probing, Double Hashin Probing 방법이 있습니다.
<참고>
Linear Probing : h(k), h(k) + 1, h(k) + 2 ... 순서로 검사하여 처음으로 빈 슬롯에 저장
Quadratic Probing : h(k), h(k) + 1^2, h(k) + 2^2, h(k) + 3^2 ... 순서로 검사하여 처음으로 빈 슬롯에 저장
Double Hashing : 서로 다른 해시 함수 h1과 h2를 이용한다.
ex) m = 13
h1(k) = k mod 13
h2(k) = 1 + (k mod 11)
5. Stack과 Queue에 대해서 설명해주세요.
스택은 선형 자료구조로 마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO(Last In First Out)방식의 자료구조입니다.
큐는 선형 자료구조로 처음에 저장한 데이터를 가장 먼저 꺼내게 되는 FIFO(First In First Out)방식의 자료구조입니다.
6. Heap에 대해서 설명해주세요.
힙은 우선순위 큐를 구현하기 위해 고안된 완전이진트리 형태의 자료구조입니다. 여기서 우선순위 큐란 우선순위가 높은 데이터가 먼저 나가는 형태의 자료구조로 힙은 데이터의 최대값과 최솟값을 빠르게 찾을 수 있습니다.
힙의 특징은 완전이진트리 형태라는 것과 부모노드와 서브트리간의 대소 관계가 성립한다는 것 그리고 중복 값이 허용된다는 것입니다.
또한, 힙은 크게 두 가지 종류로 나눌 수 있는데 최대 힙의 경우에는 부모 노드의 키 값이 자식 노드보다 크거나 같은 오나전이진트리이고 최소 힙의 경우에는 부모 노드의 키 값이 자식 노드보다 작거나 같은 완전이진트리입니다.
힙의 삽입 삭제 시간 복잡도는 O(logn)이며 힙 정렬의 시간 복잡도는 O(nlogn)입니다.
7. Tree, Binary Tree, Binary Search Tree, AVL Tree에 대해서 설명해주세요.
트리란 노드들이 나무 가지처럼 연결된 비선형 계층적 자료구조입니다.
이진트리란 자식노드가 최대 두 개인 노드들로 구성된 트리입니다.
BST란 이진트리로써 노드의 왼쪽 하위 트리에는 항상 노드의 값보다 작은 값이 존재하고 오른쪽 하위 트리에는 항상 노드의 값보다 큰 값만 포함되는 구조이고 중복을 허용하지 않는 특징을 가지고 있습니다. 평균적으로 삽입, 검색, 제거는 O(log(N))의 시간복잡도를 가지고 있습니다.
그러나 BST Tree는 한쪽으로 치우친 편향 이진트리가 되면 O(N)의 시간복잡도를 가지게 됩니다. 이를 방지하고자 높이 균형을 유지하는 것이 AVL 트리입니다. AVL 트리는 왼쪽, 오른쪽 서브 트리의 높이 차이가 최대 1이라는 특징을 가지고 있습니다. (O(log(N)))
8. 트리 순회 방법에 대해 설명해주세요
트리 순회 방법은 전위순회, 중위순회, 후위순회, level 순회가 존재합니다.
전위순회의 경우 뿌리 노드를 먼저 탐색하고 왼쪽 자식 노드와 오른쪽 자식 노드 순서로 순회하는 방식입니다.
중위순회의 경우 왼쪽 자식 노드를 먼저 탐색하고 뿌리 노드와 오른쪽 자식 노드 순서로 순회하는 방식입니다.
후위순회의 경우 왼쪽 자식 노드를 먼저 탐색하고 오른족 자식 노드와 뿌리 노드 순서로 순회하는 방식입니다.
level 순회는 트리마다 층이 존재하게 되는데, 해당 층 즉, 레벨 순서대로 순회하는 방식입니다.
9. BST의 최악의 경우의 예와 시간복잡도에 대해서 설명해주세요.
만약, 1부터 10까지 수를 순서대로 삽입한다면 BST가 오른쪽으로 쏠려있는 편향된 트리의 모양을 가지게 됩니다. 이 경우에는 삽입, 삭제를 진행하면서 처음부터 끝까지 계속해서 수행해야하므로 O(n)의 시간복잡도를 가지게 됩니다.
10. DFS, BFS에 대해서 설명해주세요.
깊이 우선 탐색은 최대한 깊이 탐색한 후 더이상 깊이 갈 곳이 없을 경우 돌아와서 다시 최대 깊이를 탐색하는 방법입니다.
너비 우선 탐색의 경우에는 인접한 노드를 먼저 탐색하는 방법으로 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨여지 있는 정점을 나중에 방문하는 순회 방법입니다.
DFS의 장점은 BFS에 비해 저장공간의 필요성이 적다는 것이고 최단경로를 보장할 수 없다는 것이 단점입니다.
BFS의 장점은 최단경로임을 보장한다는 것이고 단점은 큐라는 자료구조를 활용하기 때문에 노드의 수가 많을수록 큰 저장공간이 필요합니다.
11. 알고있는 정렬 알고리즘의 종류에 대해서 말하고 각각의 특징을 간단하게 설명해주세요.
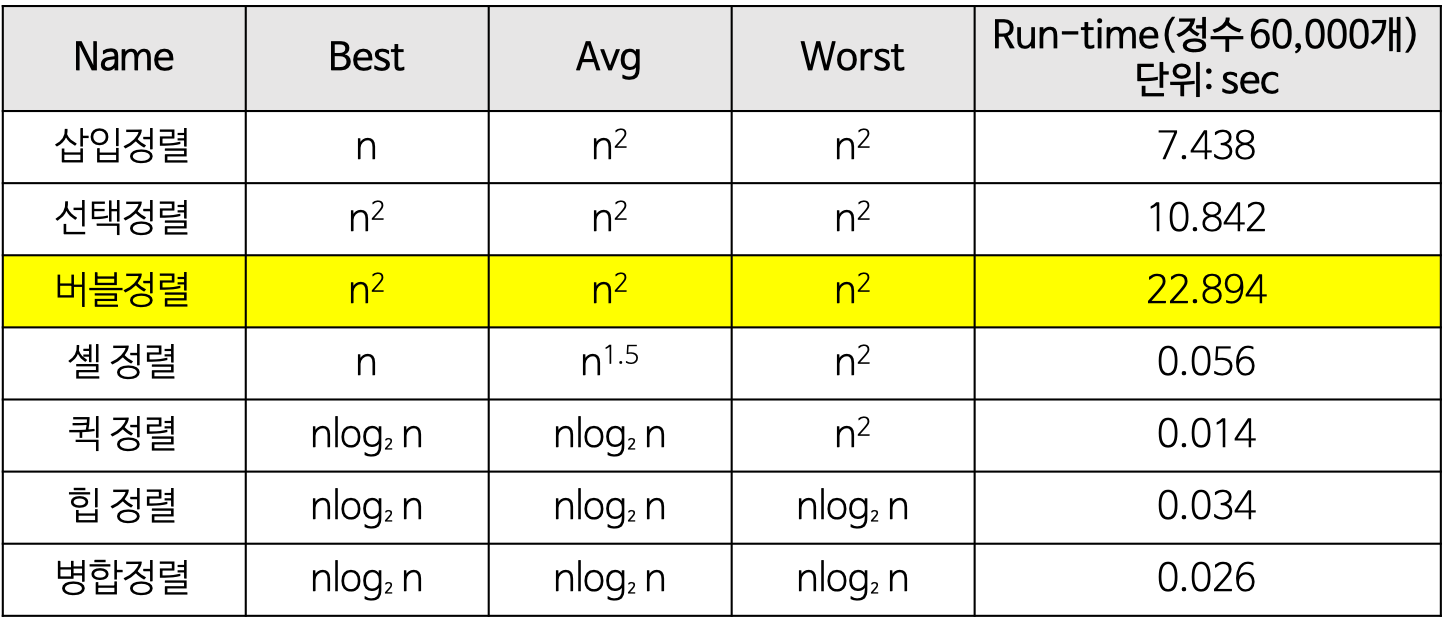
선택 정렬, 삽입 정렬, 버블 정렬, 퀵 정렬, 힙 정렬에 대해서 알고 있습니다.
선택 정렬은 최대값 또는 최소값을 찾아 현재 인덱스와 변경하는 방식으로 평균적으로 O(n^2)의 시간복잡도를 가집니다.
삽입 정렬은 현재 위치에서 그 이하의 배열들을 비교하여 자신이 들어갈 위치를 찾는 방식으로 평균적으로 O(n^2)의 시간복잡도를 가집니다.
버블 정렬은 매번 연속된 두개 인덱스를 비교하며 교환하는 방식입니다. 평균적으로 O(n^2)의 시간복잡도를 가집니다.
퀵 정렬은 pivot point라고 기준이 되는 값을 하나 설정하여 이 값을 기준으로 왼쪽 오른쪽으로 분할하여 정렬하는 방식입니다. 이렇게 진행하면서 분할된 배열의 크기가 1이되면 종료됩니다. 평균적으로 O(nlogn)의 시간복잡도를 가집니다.
힙 정렬은 우선순위 큐를 구현하기 위해 힙을 활용하여 정렬하는 방식입니다. 평균적으로 O(nlogn)의 시간복잡도를 가집니다.
<참고>
12. Stable, Unstable 정렬에 대해서 설명하고 대표적인 예를 들어보세요.
stable sort란 정렬을 할 경우에 같은 값이라도 상대적인 위치가 유지되는 방식입니다. 종류로는 버블 정렬, 삽입 정렬, 병합 정렬이 존재합니다.
unstable sort란 정렬을 할 경우에 값은 값이라도 상대적인 위치가 보장되지 않는 방식입니다. 종류로는 선택 정렬, 힙 정렬, 퀵 정렬이 존재합니다.
13. 순차탐색, 이진탐색, 해시 탐색의 차이는 무엇인가요?
가장 큰 차이점은 시간복잡도라고 생각합니다.
순차(선형)탐색은 초기 리스트를 처음부터 끝까지 탐색하는 방법으로 시간 복잡도는 O(n)을 가지고 있습니다.
이진 탐색은 중간값과 계속 비교하며 탐색하는 방법으로 시간 복잡도는 O(logn)을 가지고 있습니다. 그러나 반드시 정렬이 되어 있어야하며 중복되는 숫자가 없어야 합니다.
해시 탐색은 미리 데이터와 저장한 곳의 주소를 연결함으로써 짧은 시간 내로 탐색하는 방법으로 시간 복잡도는 O(1)을 가지고 있습니다.
'면접준비' 카테고리의 다른 글
| [기술 면접] 스프링 / 보안 (0) | 2022.12.23 |
|---|---|
| [기술 면접] 데이터베이스 (0) | 2022.12.22 |
| [기술 면접] 운영체제 (0) | 2022.12.20 |
| [기술 면접] 네트워크 (0) | 2022.12.19 |
| [기술 면접] 객체 지향 프로그래밍 (0) | 2022.12.16 |